 Figure
1. Mainline variants
Figure
1. Mainline variants Advanced SCM Branching Strategies
Stephen Vance steve@vance.com Copyright � 1998, Stephen Vance. Permission is granted for Perforce Software, Inc. to copy and distribute.
Abstract
In Software Configuration Management (SCM) systems, branching allows development to proceed simultaneously along more than one path while maintaining the relationships between the different paths. It is a fundamental technique behind any well-organized large-scale development, maintenance, and release effort. Branching strategies sufficient for small-scale efforts are inefficient and counterproductive when applied to large-scale efforts.
In this paper, I first define branching in a general sense. I then discuss various strategies for branching, starting with the obvious and moving up to several that are more appropriate for larger development efforts. Along the way, I discuss the pros and cons of each strategy, using them to motivate the changes that compose the more complex strategies.
These strategies are based on experience with several SCM systems on development projects ranging from tens of thousands to several million lines of code. These projects were developed by up to several dozen people concurrently, some in an internationally distributed environment.
Introduction
Branching is a relatively simple mechanism. Its sophisticated interactions with technical and managerial issues confound and stymie many. The most obvious reason for branching is to start an alternate line of development. This explanation is so generic as to encompass all reasons for branching. Practically speaking it is only marginally useful. It is more appropriate to ask under what circumstances one would want to start an alternate line of development in the development process. To answer this question, we must understand where a branch begins and what a branch represents in the development environment.
At the heart of any organization?s development infrastructure is the SCM tool. The SCM system as a whole consists of the customizations and policies necessary to adapt the SCM tool to the way the organization wants to use it. In some cases, the organization must adapt to the way the SCM tool needs to be used. Regardless, the state of the practice in SCM is to buy a tool and then figure out how it should be used.
This paper advocates a planning and analysis based approach to the significant issue of branching. It begins with a quick overview of the strategies most organizations try, concluding with a statement of the assumptions used throughout the rest of the discussion. From there, a discussion of codeline policy and codeline ownership follows, with deeper treatment of branchpoints, merging and branch life span. Next the concept of branch roles is introduced and applied to the common task of release management. Within this conceptual framework, specific examples of release branching strategies are built up and examined. Finally, the discussion concludes with coverage of specialized branching topics: projects spanning releases, derivative development projects, distributed development, and some unusual variations.
The Obvious Strategies
This section describes how organizations typically discover and grow into SCM. It concludes with a summary of the level of SCM maturity that is expected as a foundation for the rest of the paper.
When the issue of how code should be managed in an organization first arises, many companies define mechanisms to maintain source in some directory structures. They define methods to facilitate various self-evident issues, such as overwriting each other?s changes, checkpointing, and code replication and integration. For example, there may be a script that invokes the editor only if some well-known file does not exist. Copies of the source base may be made periodically to capture some release state. Ports may be accomplished through copying the source and manually reintegrating the changes.
Later, an organization may find one of the various freely available SCM tools, such as RCS [TICH85], SCCS [ROCH75] or CVS [BERL90]. At first it will likely develop entirely on the trunk, the sequence of versions that develops when no branching is used. Eventually, features like locking, labels, numbering, and branching may be discovered, but are seldom used effectively. Up to this level, an organization lacks the maturity to plan many of their processes, eliminating the possibility of many useful but more complex strategies for the management of their development environment. Similarly, the tools that are being applied are limited in their capabilities to flexibly address the issues.
The organization applies branching strategies to its environment without realizing it. They are defining policies, rudimentary though they may be, that govern how concurrent development and releases are managed.
Several problems are typically encountered and overcome through this stage of an organization?s growth. We will assume for this discussion that these problems have been encountered and overcome. We will make the following assumptions about how an SCM environment is managed:
Developing Branching Strategy and Codeline Policy
This section defines the critical concepts of a codeline policy, a codeline owner and a branching strategy. Three main attributes of a branch are identified and discussed to assist in the formulation of codeline policy: branchpoints, merging policy and branch life span.
A codeline policy describes the rules governing check-ins, merges and other uses of a codeline. Each branch has an associated codeline policy dictating how it should be used. [WING98] advocates codeline policy, and recommend that one should branch on incompatible policy. Therefore, a new branch should be created when changing development needs require a change in the current codeline's policy. A branch provides a mechanism by which one can support a newly required set of policies without changing the policies that are already in effect.
Codeline policies should not be arbitrarily invented. They are derived from the organization?s software development requirements. They are shaped by the answers to a number of detailed questions about how a company releases its software, how they plan to develop their software, and what range of software packagings they need to produce. Within an organization, certain sets of these answers will define common approaches to development, and many codeline policies will resemble each other. Bear in mind that not all codeline policies apply in all company?s environments.
[APPL98] and [WING98] both recommend that each codeline have a codeline owner. It is the codeline owner's job to rule on any questions regarding the codeline policy and to ensure that any maintenance issues defined or inferred in the codeline policy are successfully carried out. Sometimes the codeline owner will do the integration, but he is at least responsible for delegating it.
A branching strategy consists of the guidelines within an environment for the creation and application of codeline policies. Creating a branching strategy consists of:
In addition, there needs to be an owner of the branching strategy who will have final judgment on changing policy guidelines.
A codeline policy identifies how a branch should be used, but this assumes that the branch exists. The branching strategy sets parameters for the issues relating to branches creation, interaction, and retirement. These aspects of the branch's lifetime are represented by the branchpoint, the merging policy, and the branch life span.
Generally, the branchpoint is fully defined before the branch is created for use. The full specification of a branchpoint usually occurs through a label, but can also be described by date and time or specific version numbers. Although other branchpoint creation strategies exist, they are not within the scope of this discussion.
Identification of the need for a branchpoint occurs when the need for a different type of project causes a change in branch policy. Any new project or type of project on any branch carries with it the possibility to require a new branch, and therefore to define a branchpoint.
Merging is the process by which one codeline is integrated into another. Merging occurs when there is utility in applying any set of changes on one branch to another branch. Generally, merging is relevant when the source and target branches have common ancestors. Ancestral relationships beyond those having a common immediate branchpoint have varying levels of support in SCM tools.
The merge policy of a branch describes how frequently the branch is merged to other branches. This policy can be divided into the import policy and the export policy. The import policy for a branch defines when the codeline owner should have work on other branches merged to it. The export policy is usually defined with respect to recognizable characteristics of the development assigned to the branch, such as stability or completeness. It also may be responsive to other events, such as imports and other incoming merges, time intervals, or the branch's life span.
Life span refers to the amount of activity between branch creation and decommissioning. Life span is a qualitative attribute, not a quantitative measure. A branch?s life span is discussed as it compares to that of other branches.
In summary, a codeline policy defines the rules governing the use of a codeline or branch. A branching strategy consists of the guidelines for creating and applying codeline policies within an organization. Its primary purpose is to define a collection of template codeline policies that can be applied to form a coherent development environment. As a codeline has an owner to resolve ambiguities in a codeline?s policy, a branching strategy should also have an owner to resolve conflicts between codeline policies and to mentor the creation of new ones.
Branch Roles and Release Management
This section discusses five roles that branches can fulfill in the process of release management: mainline, development, maintenance, accumulation, and packaging. These roles are individually addressed and applied to aspects of a prototypical three-level release structure. Each role is defined and discussed with respect to the three attributes of branchpoint, merge policy, and life span. A discussion of the role of risk in the application of roles to a release branching strategy is included. Factors of risk guide many of the decisions in performing release management in an SCM system.
Most software development efforts have some form of incremental deliverables, usually manifested as a series of releases. For this reason, we will discuss the relationships between branching and release management. There are five main roles that need to be considered for branches in planning toward the goal of a single release:
Note that the same branch can fill two roles. Roles do not require their own branch, so long as the role policies do not compete or their influences can be reconciled.
Typically, there are two to three levels of release, named by numbers connected with periods (e.g. 1.2.3). This paper works with a three level release structure for greatest applicability. The assignment of sequential numbers and a hierarchy of change semantics are not intended to suggest that this scheme corresponds to the scheme determined by an organization?s marketing department for public consumption. Many have argued that the two should have no correspondence between them, even suggesting the use of code names internally as the only designator for a release. This paper takes the more moderate position that a correspondence can exist so long as it works for both purposes. If a hierarchical structure best communicates the semantics of the environment, use it and let the marketers invent a structure that suits their needs.
In this structure the first number is associated with a major version, indicating that it has significant feature and functional enhancements from the previous; there may also be significant incompatibilities that require migration. The second number represents a minor version, which contains lesser feature and function enhancements, a significant number of bug fixes, and no incompatibilities. The third number refers to a patch level, signifying almost exclusively a collection of bug fixes; no feature or function enhancements and no incompatibilities are allowed between patch levels.
It can be easily seen that even within a particular type of release, there can be several different kinds of development projects at work, suggesting different policies governing their management. As stated earlier, different policies suggest different branches. Therefore, any give release is unlikely to be properly represented by a single branch in the SCM tool.
The Mainline Role
The mainline is an important role in the proper management of a development effort. The purpose of a mainline is that of a central codeline to act as the basis for subbranches and their resultant merges.
The assumption present is that all of mainline's subbranches are related through an ancestor, not only through a strict version relationship, but also in purpose. Also, the fact that the mainline codeline is central implies that it is a singleton, a one-of-a-kind.
Often mainline is incorrectly bound in concept with the main branch in a version tree, frequently through the SCM tool vendor's naming. For example, ClearCase gives it the name /main [ATRI94]. Perforce is better with //depot, but some Perforce documentation suggests //depot/main for the trunk.
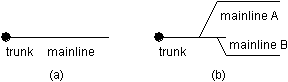
It is natural to want to consider the trunk as the
mainline as shown in Figure 1(a). It has several properties that would suggest its use for
this purpose. First, it is the branch on which most code starts its life; in some SCM
systems, all code starts on the trunk. As the primary lifeline for file creation, it is
central to all successive development and has an ancestral relationship to all
development. Since the trunk usually can not be deleted, its lifetime is guaranteed to
exceed that of any and all subbranches, making it a ripe candidate for any branch
parenting. There is no branchpoint in a mainline that resides on the trunk.
Figure
1. Mainline variants
However, in an environment with multiple independently developed products or independent component groups with differing release cycles, merging these lines of development into a common parent branch is questionable. Additionally, if there are multiple geographic locations for development, it may be reasonable to provide each site with its own mainline and synchronize their mainlines. If one site owns the trunk as its mainline, one creates an asymmetrical development environment that is unnecessarily complicated to maintain. In this case, the branchpoint of a mainline will be on the trunk, usually off of the trunk?s head revision at the time the mainline is created.
If you have only one product or family of products, do not segregate the departments internally onto differing release schedules and do not have geographically distributed development, using the trunk as the mainline is probably adequate for your purposes. If you are engaging in any of the above activities, you should seriously consider using subbranches of the trunk as the mainlines on your various projects as shown in Figure 1(b). Some of these activities will be discussed in more detail later.
Usually, the mainline will not have to deal with merge policies. Particularly if the mainline is on the trunk or the various mainlines are mutually independent, there is nothing with which the mainline should synchronize. However, in the event of multiple mainlines, such as one might use to support distributed development, the mainline may have a merge policy in order to synchronize mainlines. Some specifics are given below in the discussion on distributed development.
The life span of the mainline is the life span of the code base. In a strict release model, the mainline will have the longest life span of any branch. This is not necessarily the case in a more true-to-life production environment or with projects that do not have to obey a release cycle. In distributed development it may be shortened in some cases to the life span of development at that location. In an environment with multiple mainlines, the code base in question is the code associated with the product or component that motivated the creation of the mainline.
The Development Role
Development is the activity that produces the feature and function enhancements that characterize major and minor releases. Several branches in each release are likely to assume this role. The key concept behind development is the creation of new functionality, generally a higher risk activity than the simple fix.
Discussion of development introduces risk into the equation of branch creation, a topic that deserves elaboration. Risk mitigation is the single largest force driving the evolution of software life cycle models. In the context of a life cycle, insulating the overall system?s exposure to a change reduces risk. Tackling the change in ways that reduce the investment or limit the impact does this. The waterfall model tried to reduce risk by planning a detailed road map in advance. Recognizing the impossibility of this approach in most practical situations, the spiral model calls for contained cycles of incremental development followed by review and preceded by corrective planning. Other approaches such as RAD and Rapid Prototyping continue this trend.
Branching works cooperatively with these life cycles by providing a mechanism for physically isolating riskier development ventures from the code base. This allows the project leadership to have all of the benefits of SCM without imposing unstable code on the rest of the developers.
In general, consider using separate branches for each high-risk project. High risk projects are characterized by large size, large numbers of people, unfamiliar subject matter, highly technical subject matter, very tight time lines, uncertain delivery dates, incomplete or volatile requirements, and geographically distributed project teams. Similarly, consider designating a single branch for low risk development in each release. Several sources including [WING98] recommend using the mainline for this purpose. Consider the factors discussed above for the mainline before committing to this course of action. Low risk development may have different policy from the mainline even if you have multiple members of a product family coordinating through the mainline.
At the time the development is started both low- and high-risk development branches almost always will have their branchpoints on the mainline as the head revision. Subprojects of high-risk development will have their branchpoint as the head revision on the parent development branch when the sub-project is started. An independent low-risk development branch will usually share a branchpoint with the mainline, use the first revision of the mainline, or branch from the head revision when the first low-risk project is started.
In a release environment, development branches will always have a merge policy. This merge policy may not be invoked in the event that a particular development is cancelled, but it will have been defined regardless. The policy is usually one of merging to the parent branch when the development is finished. Sometimes in incremental or distributed development this structure will be more complex. We will deal with those cases below.
Development branch life span is usually the duration of the development project effort. Sometimes, HRD will require fixes in the release cycle in which it was developed. Some organizations have these fixes also occur on the development branch, therefore extending the life of the branch. This approach to development will also have an impact on the merge policy for the branch.
The Maintenance Role
Maintenance usually designates bug fixing activities. Analysis of maintenance branching is very similar to that of development branching in that a risk based approach clarifies many of the issues. Most bug fixes can be characterized as lower risk than almost all development projects. It is usually acceptable for bug fixes for a release be performed on the mainline. In this case there is no branchpoint that is distinct from the mainline?s.
Environments in which the mainline must remain stable with high reliability will want to move bug fixing to its own branch. This branch clearly has different policy from both mainline and from low-risk development. In this situation the branchpoint will be determined like the branchpoint for low-risk development was previously.
There is a category of bug fix that should be considered for its own branch. In any code base, particularly as it ages, situations arise in which a bug fix can have a highly destabilizing effect. This is more likely tied to the nature of the bug. It occurs more frequently when the code base is being pushed well beyond the limits of its original design. The branchpoint here will be determined like the branchpoint for a high-risk development project. This is an example of what [APPL98] refers to as an Activity Branch.
For maintenance, the merge policy is usually as simple as or simpler than the development policy, primarily because the scope of the maintenance projects is smaller. Distributed development can complicate maintenance merge policies, as well, but often this is handled the same way as mainline, accumulation line or development.
Obviously, when the maintenance is performed on the mainline, life span is not an issue. When it is performed on its own set of branches, the policies tend to look like development policies.
The Accumulation Role
Toward the end of each release cycle, the need arises to consolidate the efforts of various activities that required their own branch. Depending on the quantity of branches and the significance of their changes, the integration of a release effort can be a project in itself. This factor alone is a risk in the planning of the release as a whole. This risk can be mitigated through the "Propagate Early and Often" tenet in [WING98].
The branch satisfying the accumulation role acts as the focus for merging the final results of various subbranches. Often accumulation takes place by merging to the mainline. Here, as we saw in the case of low-risk fixes, the accumulation branch is indistinct from the mainline and therefore has no branchpoint of its own. Similarly, unless multiple related mainlines are in effect, it has no distinct merging policy. The branch?s life span in this model is identical to that of the mainline.
However, sometimes it is necessary to merge to a branch independently from the mainline as an intermediate step. This would be followed by a merge from the accumulation branch to the mainline. This strategy is recommended in two situations. First when the code base is large and the changes that have not been merged back to mainline are substantial. Second when the integration team has several people that need to share intermediate integrated state. In the latter case, the branchpoint is usually identified by the head revision of the mainline when the integration needs to take place. The merging policy for such a branch will minimally indicate that the accumulation will be merged to the mainline when the accumulation is finished. Additional intermediate merges may be called for depending on the accumulation branch?s stability and content. This branch will tend to have a short life span, spanning only the time necessary to integrate the projects and fix any conflicts.
Another way to accumulate that is useful in an environment requiring a high-reliability mainline, is an accumulation branch that parallels the entire mainline. In this case the branchpoint would be that of the mainline, the first version of the mainline, or the head of the mainline when the first accumulation is required. The merging policy in this situation can require considerable thought to achieve regularity and consistency, particularly in a multiple mainline environment. This model?s accumulation branch has life span almost as large as mainline?s, but is shorter due to the eventual merge to mainline for packaging.
The Packaging Role
The packaging role is often confused with the accumulation or, more commonly, mainline roles. Once the intended development and maintenance have been performed and any accumulation has been done, it is time to prepare the code for release. Such an effort may not be trivial, requiring a team of release engineers and additional fixes beyond those already performed. The policy on a packaging branch is significantly different from that on a maintenance branch, as the packaging role suggests, only the changes necessary to make the product releasable should be addressed.
If work is to proceed on the other product branches, as is likely to happen if patch levels of the product are to be produced, one does not want the release effort to stall progress toward the next patch level. Other packaging branching strategies could even keep minor versions running off of the same mainline, compounding the potential for a stall while the packaging activity takes place.
Using a separate branch to insulate the release effort from the ongoing development and maintenance, and vice versa, is recommended. In a multi-platform environment, it may be advisable to create one packaging branch per platform for the final porting effort. If the porting efforts are staggered, this allows the staggered releases to be reflected in the version hierarchy. If the porting efforts are simultaneous, accumulating the per-platform packagings to a master packaging branch, from which the final build would be performed, should also be considered. This should be determined in advance, as creating the separate packaging branches from the master packaging branch works best.
In any case, the branchpoint for the primary packaging branch should be either the head revision or the latest stable revision of the mainline. Some strategies will want to use the accumulation branch instead of the mainline where they are distinct. The branchpoint for each packaging branch should be the head revision of the master packaging branch.
Packaging branches tend toward the same rules that apply to development in a single-site environment. Even in a distributed environment, the release responsibility usually resides at one location. Therefore, the packaging branches tend to exist only off of one mainline and do not need to be reflected at other sites. They also tend to be merged when they are complete, and their results are propagate to other locations through the merge policy of their parent branch, either mainline or the main accumulation branch. Even a packaging accumulation branch is usually owned by one site.
A packaging branch will have life span similar to that of a development branch for a small- to medium-sized development project. A packaging accumulation branch may have a slightly longer lifetime, lasting until all of its subordinate branches have expired.
Branching Roles Summary
There are five branching roles that can be applied to release management: mainline, development, maintenance, accumulation, and packaging. Within a release branching strategy, there may be a many-to-many mapping between roles and branches.
The mainline role is the central codeline around which all other branches are coordinated. The mainline does not necessarily reside on the trunk of the version tree.
The development role is applied to branches supporting the creation of feature and functional content of a product. The primary motivation for the development role is the mitigation of risk in the development process. Risk mitigation is accomplished by using branches to isolate development from other streams of activity and vice versa. Once the development effort has been stabilized, it can safely be merged into the main flow of progress without putting the whole organization?s efforts at risk.
The maintenance role is associated with bug fixing and is characterized by low-risk activities. There are ways to manage these low-risk activities with less overhead than would be warranted for development. Once again, risk is the motivating influence and certain maintenance tasks may call for more effective risk mitigation strategies.
The accumulation role provides a means for multiple activities to be safely integrated without corrupting the main flow of activity. This recognizes that some integrations can have a high associated risk, and that sometimes parallelizing integration and ongoing efforts can cause instability in the environment.
Finally, the release role highlights the need to restrict efforts to only those fixes necessary to release the product on all target platforms. Strategies were addressed to allow the release effort to proceed in parallel with ongoing maintenance and development activities.
Example Release Branching Strategies
The above discussion is somewhat abstract. Where the discussion was concrete, it focused on small building blocks in the overall release scheme. This section zooms out a level, and applies the abstract to three realistic release scenarios. These strategies do not encompass all possible strategies. Such a task is impossible. Instead they provide a foundation strategy which shows how the components fit together and provides two expansions on it to address specific needs. The rationales provided as each strategy is elaborated serve as examples that the reader can use to develop their own release branching strategy.
Basic Release Strategy
Let's start with a simple but complete scenario that
one might adopt, shown in Figure 2. For this example, the organization has only one
product and performs work on each release sequentially. Therefore, the mainline is on the
trunk. Additionally, since the products in question are relatively small, perhaps on the
order of 100-200KLOC, the accumulation role is on the mainline. 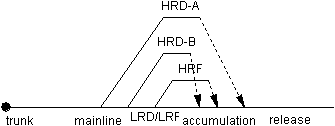 Figure 2. Basic release branching strategy Since the development team is small, everyone is dedicated to the release
effort or temporarily redirected to efforts that do not modify source code during the
release effort. This allows the release effort to also take place on the mainline,
avoiding conflict with any ongoing development. This works particularly well if there is
only one platform for release or the platforms have little differentiation.
Figure 2. Basic release branching strategy Since the development team is small, everyone is dedicated to the release
effort or temporarily redirected to efforts that do not modify source code during the
release effort. This allows the release effort to also take place on the mainline,
avoiding conflict with any ongoing development. This works particularly well if there is
only one platform for release or the platforms have little differentiation.
During development, all low-risk development (LRD) and low-risk bug fixes (LRF) are performed on the mainline. The assumption here is that none of these projects have the likelihood to destabilize the code base or to require intermediate check-ins for checkpointing that would have significant effect on other developers. It is likely that these changes would be accomplished entirely in the client view and checked in when finished.
The high-risk development (HRD) projects A and B in the example are performed on their own branches. This activity keeps them isolated from the mainline development until, as shown in the example, they are completed and merged to the mainline. A single high-risk bug fix (HRF) is similarly handled.
Basic Release Strategy with Packaging Branches and Intermediate Accumulation
Next, let us consider the slightly more complex
strategy shown in Figure 3. In this example, we will still assume that the organization
only has one product and that products are released sequentially. Thus, we keep the
mainline as the accumulation branch and put it on the trunk.  Figure 3. Basic release development with
intermediate accumulation and packaging branches
Figure 3. Basic release development with
intermediate accumulation and packaging branches
We still try to isolate our HRD projects. However, projects A and B both affect the some of the same parts of the system, so we anticipate merge conflicts in their changes. We decide to mitigate the risk of this overlap by setting up an intermediate accumulation branch. As soon as either project is ready to merge, we create the accumulation branch. The diagram shows the accumulation branchpoint as distinct from either project's branchpoint. However, the task could be simplified even further by making the branchpoint identical to that for project B. Doing this would have the effect of removing the intermediate mainline development from the accumulation merge and further reducing the risk of difficulties. Notice that not all HRD has to be merged to the intermediate accumulation branch. Nor does it required that the intermediate accumulation branch service only two projects or be unique within a release cycle. When the intermediate accumulation has been successfully completed, it is merged back into the main accumulation branch, in this case the mainline.
Multiple Mainline Strategy Due to Multiple Products
Now let us assume that the company has multiple
products, in Figure 4 there are two, based on a common core, but otherwise independent.
The trunk holds the branchpoints for the core mainline and each of the product mainlines.
The three mainlines each look almost exactly like the mainline in the previous example.
However, their policies differ significantly, primarily in their starting compositions and
in their merge policies. 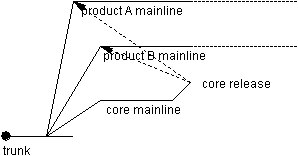 Figure 4. Two mainlines for products
based on a core development mainline
Figure 4. Two mainlines for products
based on a core development mainline
The core mainline has its own release schedule, but its releases are the basis on which the product mainlines are built. There are significant decisions an organization must make for this model to work. The primary decision is how the core will be incorporated into the products. The three variants discussed below are simply key points along a continuum. It is up to the organization to define where on this continuum they wish to fall.
The core can be a pure client to the products, in which it would be treated much like a third-party library might. Note that by defining this method of dealing with core, we suggest a method for dealing with third-party libraries. Such a strategy would develop the core to release readiness, then build and check in the resultant libraries and headers. By merging the core release to a mainline dedicated to its release representation, its opacity could be protected, or it could be repackaged. If neither protection nor repackaging is required, a packaging branch for the core serves the purpose, as shown in Figure 4. Products would then either refer to the release package as the basis for their builds or they would merge the release package into their own build structure, depending on organization policy or product structure.
The core can also be seen as being given to the products with a source code license. Once again, this may also reflect a type of third party relationship. The management of this model will be similar, except that a release package mainline may be considered writable to include bug fixes applied by the product teams. However, changes can be controlled and reviewed more easily if such fixes take place in the version of the core release merged into the individual product mainlines. Fixes applied at these levels may be merged back into the true core mainline at the core team's discretion.
Another variation occurs when the core is more tightly coupled with the products. In this model, the core team defines the majority of the core's functionality, but the product teams make modifications in the same source base. In this model, the concept of a core release is somewhat vague, as is the ownership of the core itself.
None of these models are fully reflected in any branching diagram. Their visible manifestations are the supporting mainlines, branches and merge lines, but these do not tell the complete story. The full model can only be conveyed through a larger policy definition whose further details are outside of the scope of this paper.
The product mainlines are composed of some synthesis of the core release package and their own course of development. At their beginning, they merge from a well-defined version of the core release. Possibly they incorporate more merges as core patch levels are released. If they are operating with a source license or tightly coupled relationship to the core, there may be merges from the product mainlines back into the core. Otherwise, the product mainlines operate like the previous model.
Representing Release Levels through Branches
Many organizations try to tackle the issue of assigning release levels to branches without identifying the salient characteristics of the various types of development and how they motivate branching structures. Now that a foundation for organizing release development with branches has been established, we can meaningfully identify what branching strategies best serve the typical release configurations. As discussed above, most organizations need to deal with major, minor and patch level releases. Based on our discussion of branching roles and example application of these theories, we can extend the framework to encompass larger pieces of the development cycle. This section organizes the release branching strategies outlined above into units that are meaningful to the three major release levels. We then provide specific rationale against what [WING98] calls the "promotion" model of codeline management.
Major Versions
Major versions are characterized by significant
feature and function content changes, often accompanied by compatibility issues. The heavy
development requirements of a major release suggest that each major release should be
assigned its own branch from the mainline. Figure 5 shows an arrangement in which each
major release is given a submainline off of the product mainline. Regardless of whether
the product mainline is the trunk, a branch off of the trunk or even deeper, it is
advisable to provide a major release effort with a branch off of the mainline which should
minimally act as the accumulation branch for the release content development. 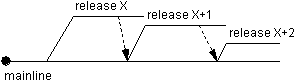 Figure 5.
Concurrent major versions from the same mainline
Figure 5.
Concurrent major versions from the same mainline
Notice in Figure 5 that release X does not necessarily stop due to the advent of release X+1. The fact that major releases can be concurrent introduces additions to the merge policy of release X. In order to ensure that changes made to release X are also present in release X+1, as will almost always be desired, the merge policy of X should state that changes made to X should immediately merge from X to X+1.
This may seem unnecessary from the perspective of small- to medium-scale development, but for large-scale development, it is essential. In fact, this merge policy arrangement is a transitive effect of two statements from [WING98]: "propagate early and often," and "get the right person to do the merge." If the correct person is performing the merge at the correct time, there is rarely a good reason for that person not to continue the propagation process to the next release. It is unlikely that another person is better qualified, and any delays will distance the person performing the merge from a clear understanding of the merge issues.
Having said that, a good reason not to merge may be when an intermediate checkpoint of a project is being propagated to the mainline. It may be a better use of the team?s time to wait until the development is more complete so as not to further destabilize X+1, which is typically under significant strain already. The person performing the merge will probably be the same, and his recollection will probably still be clear when the project is complete. A competing influence to this exception is the record keeping necessary to ensure that all changes are propagated when the time comes. Most SCM tools provide healthy support for determining what merges are necessary.
Patch Levels
Patch levels are subreleases that contain only minor fixes against a product release that is otherwise frozen in feature and function content. The ability to provide patch levels against the release version of a product can be of great importance to customers.
Generally, patch levels are easy to address. The
creation of a packaging branch off of the release mainline isolates the release effort
from any ongoing work on the mainline. The ongoing work is significantly composed of bug
fixes, providing a continuing patch effort, regardless of release efforts. This ongoing
effort provides a solid basis for additional packaging branches (or subtrees) against the
further fixed mainline. Figure 6 shows a portion of a product mainline with two different
patch level releases from it. 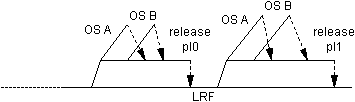 Figure 6. Multiple packaging branches from the
same mainline for patch levels
Figure 6. Multiple packaging branches from the
same mainline for patch levels
There is one issue that needs to be acknowledged when
creating patch levels through successive releases from a mainline. We discussed above that
LRD might also take place on the mainline, depending on the environment. However, this
same development is usually not allowed to take place between patch level releases. Thus,
after the first release from the mainline, LRD is no longer allowed, violating the
principle that one should branch on incompatible policy. The recommended alternative in
this event is to put low risk development on its own branch parallel to the mainline and
declare it obsolete when the first packaging branch is created. This is shown in Figure 7.
Another approach is to create patch levels from the packaging branch itself, which leads
to complicated merge policies. 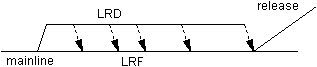 Figure
7. Using an LRD branch to resolve policy incompatibilities for patch level releases
Figure
7. Using an LRD branch to resolve policy incompatibilities for patch level releases
Minor Versions
Minor versions have attributes of both major versions and patch levels. Typically minor versions will have new feature and function development similar to that of a major version, but smaller in scale and usually without compatibility issues. Minor versions will also usually contain a significant number of fixes, often with some that are larger in scope than those that would go into a patch level.
The two primary approaches to handling minor versions are consistent with the approaches for handling major versions and patch levels. An organization with longer release schedules, a larger code base, or a larger development team should treat minor versions more like major versions. An organization with shorter release schedules, less code, or a smaller development team may consider treating minor versions like patch levels or eliminating patch levels completely.
It is difficult and usually not worth the effort to try to craft a hybrid approach to handle minor versions. Treating a minor version identically to a major version keeps the patch level releases pure to their intent without any awkward content manipulation. The tradeoff is in the number of cascading merges like those discussed with concurrent major versions.
Treating minor versions like patch levels effectively eliminates the concept of the patch level and clears up any policy inconsistency that may occur when the packaging branch is formed. It also tends to work cleanly with an environment without packaging branches, as the purpose of the packaging branch is to segregate the release effort from ongoing minor development. It does create a small window during the release effort in which mainline development should stop to ensure the purity of release builds based on release fixes. Additionally, it reduces the organization's ability to respond to changes needed at the minor version level once a particular minor version has been finalized; this can be circumvented through ad hoc branching.
The Promotion Model
There are several interpretations to the term promotion
model in SCM systems. Most promotion models are not desirable models for an SCM
strategy. In particular, this paper addresses the notion put forth in [WING98] by that
name in order to point out the deficiencies of such a model. In that model, projects and
releases branch off of each other. Figure 8 shows this model. 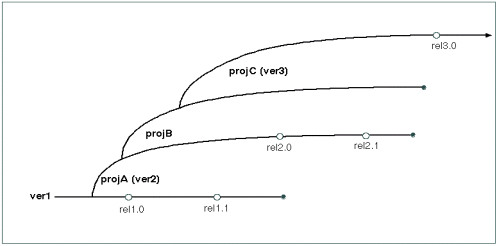 Figure 8. The Promotion Model, an example not to
follow, reproduced by permission of Perforce Software, Inc.
From "High-level Best Practices in Software Configuration
Management."
Figure 8. The Promotion Model, an example not to
follow, reproduced by permission of Perforce Software, Inc.
From "High-level Best Practices in Software Configuration
Management."
Organizations are commonly tempted to try the promotion model for very logical reasons. It is valid to think that future versions are built upon past versions. However, it is illogical to presume that one should reflect the dependency between successive versions with piggybacked branches. The fallacy of this logic is subtle and easy to overlook; logical and physical representations of a system rarely reflect each other precisely.
In [WING98] a mainline is put forth as a basic and incontrovertible principle of SCM implementation. Although substantially true, the reasons are not always clear to the less experienced SCM practitioner. Hopefully, the discussion up to this point has sufficiently justified a mainline centric model similar to that promoted in [WING98], although tuned to a larger scale effort.
Two of the primary deficiencies in the promotion model are the continually escalating complexity of merge policy and the lack of a rendezvous codeline for multiple paths of derivative development. In addition to making the management of a larger release environment more difficult, this further complicates the kinds of development discussed below, particularly distributed development.
Projects Spanning Releases
As an organization and its code base grow, the projects the organization undertakes will tend to grow as well. This growth occurs for several reasons, not the least of which is an increase in the number of products to fill new marketing targets. Successful companies also keep their customers happy, particularly outside of the shrink wrap markets, by providing frequent updates. This provides a return on investment for the customer's license maintenance fees. These two forces compete and together ensure that there will be projects whose time requirements span the normal product release cycles regardless of the release level.
Branches usually originate from and merge to other branches within the same release cycle. Projects that span releases have some conceptual complexity because they conflict with this typical usage. The project spans releases because it was estimated to take longer than a release cycle. Therefore, waiting until work on its target release has begun is not an option.
Another possible approach would be to start the release development structure for which the project is targeted based on the start of the project. This approach is likely to lead to considerable merge overhead throughout the development organization to accommodate a single project. It also may cause the paradoxical arrangement in which the development structure for a release branches sooner than the structure for one or more of its predecessor releases.
Neither of these approaches is palatable in most environments because they disrupt the normal flow of development activities for the needs of a single project. The recommended approach is to create a branch off of the latest release meets the stability needs of the project. Development should proceed on this branch until successive releases have evolved to a similar point in their ability to satisfy the project's needs. At this time a new branch should be created and the development merged to the new branch. Finally, when the release for which the project is targeted is created, the development can merge to a HRD branch in that development structure and follow the normal course of development in that release.
Depending on the nature of the project and the other development that occurs in the interceding releases, intermediate development branches may not be necessary. However, avoiding the intermediate branch increases possibility of difficulties during the merge into the target HRD release branch. The decision to avoid the intermediate branches should be taken with great consideration.
Derivative Development Projects
This section discusses the management of derivative development projects. Derivative development is based on the product code base, which is not directly intended for product release content. There are many ways to base derivative development on a product-oriented code base. Three strategies are represented here, indicating the possible variations that can be applied.
Many companies will, at one time or another, need to perform derivative development. Some examples of causes of derivative development are research grants, government contracts, proof-of-concept prototypes and customized versions of a product. Derivative projects may end up integrated with the main product development at some point in the future. They may be the basis for a rewrite for commercialization. They may acquire a life of their own as an independent product. They may reach a dead end and be retired.
There are two high-level issues that must be addressed when embarking on derivative development. The anticipation for the integration of the derivative development back into production is easy to answer, as it has much in common with projects that span releases. Additionally, since much of derivative development is not intended for reintegration, the issue of starting the project is more important. The bulk of this section will address the issue of the requirements for the foundation upon which to build.
In addressing the foundation issue, one must try to balance the stability of the foundation code base, the availability of new fixes and features in the foundation code base, and the complexity of management inherent in supporting the previous two. The next three sections discuss three approaches to a solution, and in the process, outline the solution space from which hybrid solutions can be formed. The section following addresses the answer to the second question.
A comment on life cycle issues is warranted here. Often derivative development is immune to an organization's life cycle requirements, since it is not immediately intended for product release content. In defining the organization's strategy for derivative development, one should carefully define the level of compliance required for the integration of derivative development back into the production code base. This consideration will impede the possible flow of poorly written, marginally stable, unreviewed, and otherwise unsavory development into your perfect, pristine and robust product code.
Developing from a Release Package
Developing from a release package provides the highest level of stability in the foundation code base for the project. However, unless the timing of the project coincides with the end of a release cycle, either through coincidence or fortune, one must choose between delaying the start of the project or forgoing and fixes and enhancements that have accrued since the last release. For a short-term project, one that is smaller than the typical release cycle, this decision can be significant.
The positive side of this approach is that the management complexity over the life of the project is negligible. One only needs to consider intermediate imports and exports on the derivative branch when a change in direction requires a reconciliation of the derivative functionality with the foundation code base. This situation might occur when the derivative functionality needs to be incorporated into the product immediately or changes to the foundation code base must be brought into the derivative development. The former case is somewhat ill advised; other means should be used to accomplish this goal, if careful consideration or executive ultimatum require it.
The branch for this model of derivative development should be created from the final packaging accumulation branch. Typically, the branch already will be identified with a label to make release rebuilds easier, providing an ideal foundation for a new branch.
Deriving from Development in Progress
Deriving from development in progress is probably the most realistic case of derivative development. In this model, the derivative branch is created from a (hopefully) stable point on the accumulation branch. This branch creation will require the placement of a label, or for systems that support it, the definition of specific moment in time as the base of the branch.
Although the foundation code base is not necessarily as stable as one might prefer, the latest fixes and features are present. This approach requires greater management effort, as the chance is higher that new fixes and features should be integrated into the derivative development branch. Typically, the rest of the organization is unfamiliar with the derivative development activity, so merges of their development, especially that of HRD, should not go the derivative branch automatically. Owners of derivative branches are responsible for the evaluation of each possible merge, rather than receiving them automatically.
Need-driven Branching
Need-driven branching is by far the most complicated strategy to manage, but is sometimes the correct strategy for the task. Both of the above strategies fix their branchpoint before the derivative development begins. Need-driven branching puts development for a particular source file onto the branch only at the moment when the file needs to be changed. Files that have not been changed on the derivative branch will be mapped from the foundation branch and evolve as such. Need-driven branching takes the tenet "branch only when necessary" [WING98] to its logical extreme.
Need-driven branching has a complication that requires management overhead to correct. Files changed on the need-driven branch hide later changes to the same file on the foundation branch. However, files on the foundation branch that have not spawned a need-driven branch remain fully visible as work on them continues. The difficulty in managing need-driven branching arises when foundation development changes one or more of each category of file. The complete set of foundation changes is not seen in the need-driven branch, leaving the code base in an inconsistent state.
The easiest merge policy to avoid hiding effects mandates regularly merging changes from the foundation to files on the need-driven branch. However, as in the previous examples, this activity should be the responsibility of the need-driven branch owner, not the mainstream development community.
Need-driven branching incorporates the latest fixes and features, while continuing to track their evolution and enhanced stability. However, it achieves this at the expense of management effort. Need-driven branching should be considered when the derivative development cannot be delayed to derive from the release, when the release will coincide fairly closely with the expected completion of the derivative development and when the derivative development needs high reliability as quickly as possible. Obviously, there is a considerable degree of subjectivity in assessing whether need-driven branching is appropriate. Generally speaking, need-driven branching should be avoided unless there is compelling reason to use it.
Reintegration Issues
Although the intent of much derivative development is specifically not to be integrated into the product code base, it frequently occurs that the derivative development is useful enough to charge someone other than its original sponsor money for it or some commercialization of it. When this happens, or when there was some original intent to commercialize it into product features, there is a need to reintegrate.
The approaches for reintegrating derivative development are the same as those for integrating development that spans releases. If the release already exists when the derivative development is ready for reintegration, create a HRD branch in the development structure and merge the derivative development to it. If not, one should create a branch in the latest release that satisfies the development's requirements and subsequently treat it as release spanning development.
Regardless of how the development is reintegrated into a release, this is where the life cycle compliance issues will crop up. It is recommended that all quality checks required in the regular development life cycle be applied to the final HRD branch before it is merged to the accumulation branch. The task will be simpler if the life cycle was applied to the derivative development, but this is often in conflict with the needs of derivative development.
Distributed Development
Distributed development is defined for purposes of this discussion as development carried out at multiple locations with the same common goal. Distributed development may require considerably more effort to synchronize than that of any of the previously discussed arrangements. Many factors may conspire to impede simple synchronization:
Through all of this, reducing the already high management complexity of multiple locations requires maintaining as much similarity between locations as possible. A comprehensive discussion of distributed development issues could easily be the subject of another paper. This section will hint at some of the solutions that can be adopted.
As of this writing, I am aware of only two vendors that have products that directly address the distributed development issue: Rational's ClearCase MultiSite and Continuus' DCM option to Continuus/CM. Both provide their own unique constraints on the solution to the problem.
The simplest solution is for all locations to be considered equal and to access a common source repository. This sounds like the answer is at our fingertips, and we should look no further. However, reality works against us. Reliable connections aside, many SCM systems do not support such arrangements well with their base products with usable performance. Perforce alone seems to have reasonable performance over slow connections, making this kind of arrangement somewhat feasible. However, it remains to be proven whether the performance will scale as the number of locations, number of developers, and volume of transactions grow.
An arrangement that may work well if there is a master location and several satellite locations is for each satellite location to send in batches of changes which would be checked in to a branch dedicated to the site's integration and propagated to the correct development branches. If this could be done at a time when the remote location was not working, the resultant databases could be copied back to the remote location to reflect the total development picture. However, the return update is a high-bandwidth operation and is not supported by all SCM tools. A variant could simply send back a snapshot of the latest development, requiring less bandwidth, which could be unconditionally checked in if changes had taken place. This variant ignores issues of creation and deletion of files and directories.
Another arrangement which works well in some situations is to mirror each branch on which distributed development is to take place. Each location maintains a set of branches for themselves and a set for each location. If one location is designated a master location, each location except the master can maintain only two sets of branches. In this scheme, each location has ownership of the branches for their location. The branches that correspond to other locations are read-only for development purposes and are used as intermediate accumulation branches for incoming deltas from the other locations.
Each of the last two arrangements requires considerable work on the part of the SCM maintainers to replicate branching structures and perform merges. They also put the responsibility for merges in the hands of someone who is almost guaranteed not to be the best person for the job.
Unusual Variations
There are two additional variations on branching strategies which, although not usually called for, are of some interest to the discussion of branches. These are presented more for their novelty value and to expand the reader's thinking on how branches can be used, than as a recommendation.
Call the first variation Release On Demand. In this strategy, the mainline must be kept as stable as possible at all times so that one can create a release at any time. This would be accomplished by policies mandating that no code be merged to the mainline unless it has passed considerable review and testing. This is as much of a life cycle issue as a branching issue. At the time a release is desired, simply create a packaging branch from the head of the mainline, build, test and ship. This could be used to implement a daily build [MCCO93] which would be fully repeatable should the need arise. Another application for its use would be in an environment in which the latest development is always desired, but the reliability infrastructure is large, such as one might find in a military or space program environment.
The other variant might be called the Smorgasbord Release. In this model all development that is a candidate for a particular release content is branched off of the same branchpoint. One then creates a release by picking and choosing from available contributing branches and merging them to the packaging branch. This model might be appropriate for a very indecisive environment, or when an organization is sufficiently resource rich to be willing to do development that may never make it to release content. Another situation in which this model would be useful might occur in an environment in which high levels of reuse have been attained; in this situation, the reusable components would reside on branches and be pulled into a project as needed.
Conclusion
Planning and analysis are critical to the success of any SCM system. A branching strategy motivated by a risk-based analysis of the organization?s development needs will provide a strong foundation. Incorporating the concepts of branch roles, codeline policy and codeline ownership will assist in performing the required analysis. Application of the principles of branchpoint, merge policy and branch life span will ensure that the parameters governing codeline policy are properly and completely addressed.
Once the branching strategy has been formulated, the organization can implement the customizations required to make the SCM tool suit its environment. Until SCM systems have reached sufficient maturity to address the larger issues of policy, adopting the practices put forth in this and other papers will help an organization achieve success in their software development endeavors.
References
| [APPL98] | Appleton, Brad, Stephen P. Berczuk, Ralph Cabrera, and Robert Orenstein, "Streamed Lines: Branching Patterns for Parallel Software Development," Submitted to the 1998 Conference on Pattern Languages of Program Design (PLoP'98), Allerton Park, IL, August 1998. |
| [ATRI94] | ClearCase Concepts Manual, Atria Software, Natick, MA, 1994. |
| [BERL90] | Berliner, Brian, "CVS II: Parallelizing Software Development," USENIX 1990. |
| [BOLI95] | Bolinger, Don, and Tan Bronson, Applying RCS and SCCS, O'Reilly & Associates, Inc., Sebastopol, CA, 1995. |
| [JAME94] | Jameson, Kevin, Multi-Platform Code Management, O'Reilly & Associates, Inc., Sebastopol, CA, 1994. |
| [MCCO93] | McConnell, Steve, Code Complete, Microsoft Press, Redmond, WA, 1993. |
| [PERF98] | "Networked Software Development: SCM over the Internet and Intranets," Perforce Software, Inc., Alameda, CA, 1998. Available at http://www.perforce.com/perforce/wan.html. |
| [ROCH75] | Rochkind, Marc J., "The Source Code Control System," IEEE Transactions on Software Engineering, Vol. SE-1 No. 4, December 1975. |
| [TICH85] | Tichy, Walter F., "RCS - A System for Version Control," Software Practice and Experience, Vol. 15 No. 7, July 1985. |
| [WING98] | Wingerd, Laura and Christopher Seiwald, "High-level Best Practices in Software Configuration Management," draft of a paper to be presented at the Eighth International Workshop on Software Configuration Management, Brussels, 1998. Available at http://www.perforce.com/perforce/bestpractices.html. |